操作系统学习笔记 | 4. 物理内存管理 II 非连续内存分配
为什么需要非连续内存分配
连续内存分配的缺点包括:
内存利用率低
存在内外碎片问题
分配给程序的物理内存是连续的
而非连续内存分配的优势:
更好的内存利用和管理
允许共享代码与数据(如共享库)
支持动态加载和动态链接
程序的物理地址空间是非连续的
非连续内存分配
非连续内存分配的核心问题是如何实现虚拟地址与物理地址之间的转换。可以通过以下方式解决:
软件方案
硬件方案
分段
程序的分段地址空间
分段寻址方案
分页(目前主要使用的机制)
分页地址空间
页寻址方案
分段
分段将逻辑地址空间分成不同的段,且这些段可以分散在多个物理地址空间中。如图所示,分段的逻辑视图将逻辑地址映射到不同的物理地址空间,形成程序的分段地址空间。
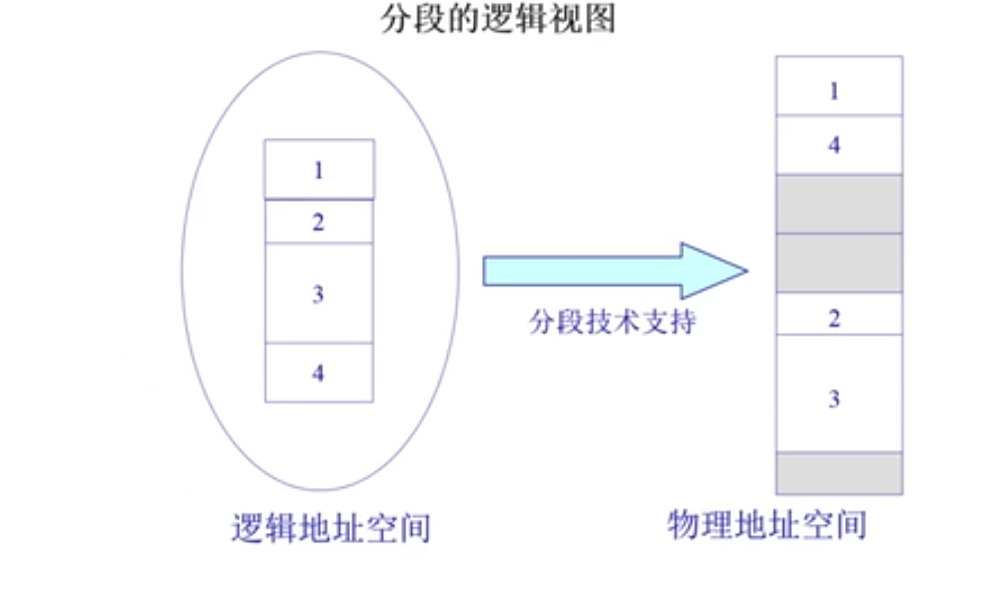
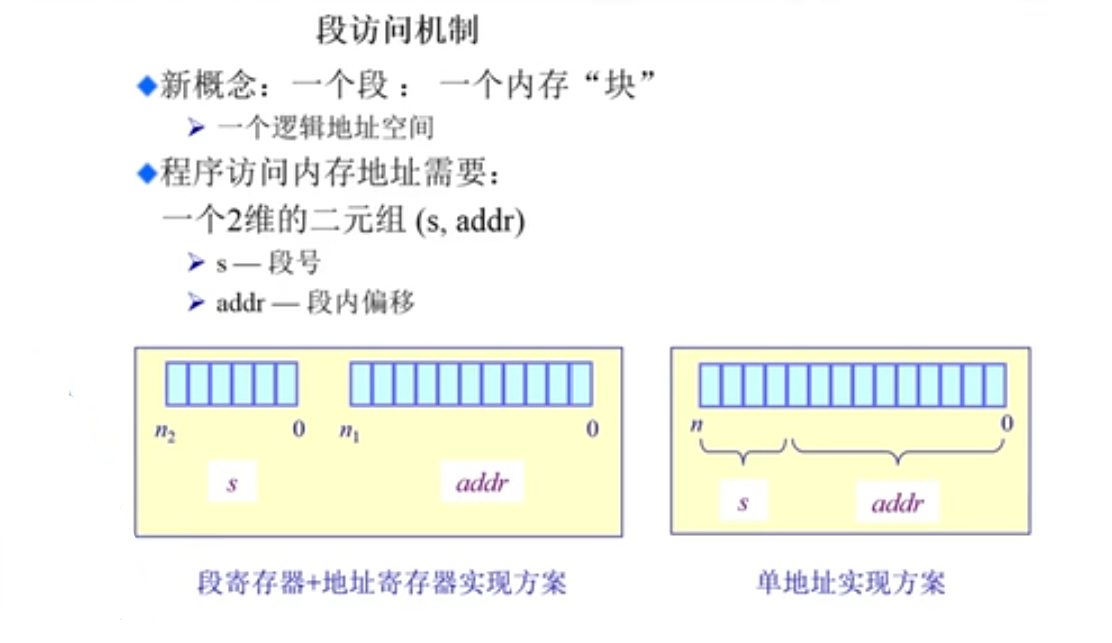
为了表示实际的地址,逻辑地址被划分为两部分:段内的寻址部分和段内的偏移部分。
如图所示,有两种实现方式:一种是使用段寄存器加地址寄存器,另一种是将段号和偏移量拼接成单一地址表示。
下图展示了分段的硬件实现方案:
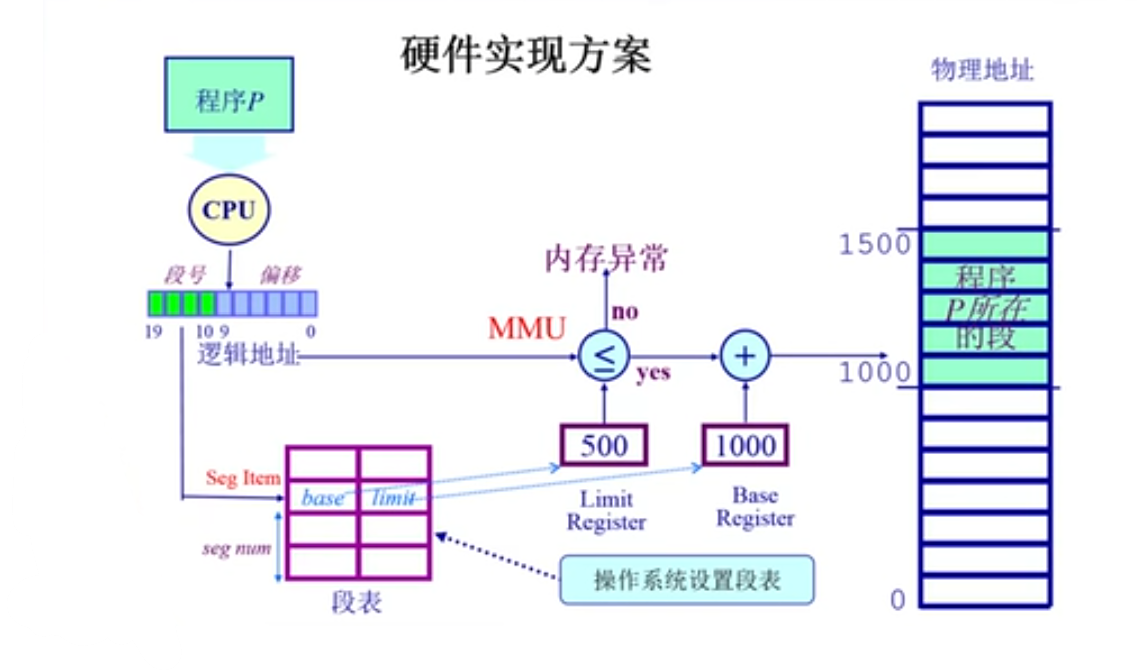
在此方案中,逻辑地址使用的是单地址表示法,一部分表示段号,另一部分表示段内偏移量。为了实现地址的映射,操作系统建立了段表,存储段的起始地址和段的长度限制。使用段号作为段表的索引,能够实现逻辑地址与物理地址之间的映射。
访问时,通过段的长度限制和实际地址来判断是否越界。若越界,访问将被视为非法,触发异常;否则,计算得出的地址可以访问实际的物理地址。
分页
分页机制的核心思想是通过页号和页内偏移量来寻址,类似于分段,但与分段不同的是:在分段中,段的大小是可变的,而在分页中,页的大小是固定的。
分页将物理内存划分为固定大小的帧(通常为2的幂,如512B、4096B等)。逻辑地址空间则划分为相同大小的页。通过建立逻辑页和物理页之间的映射关系(页到帧的映射),实现地址转换。
页表
MMU / TLB
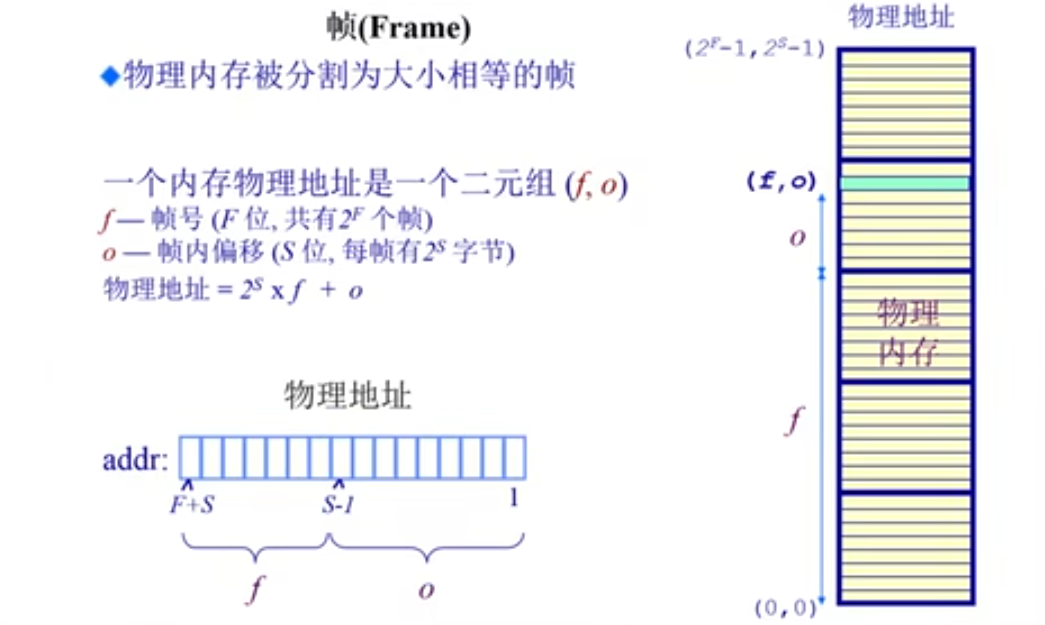
帧 (Frame)
物理内存被分割成相同大小的帧。每个物理地址由两部分组成:帧号和页内偏移量。具体的物理地址可以通过公式 address = 2 ^ S * F + offset 来计算,其中 F 是帧号,offset 是页内偏移量。
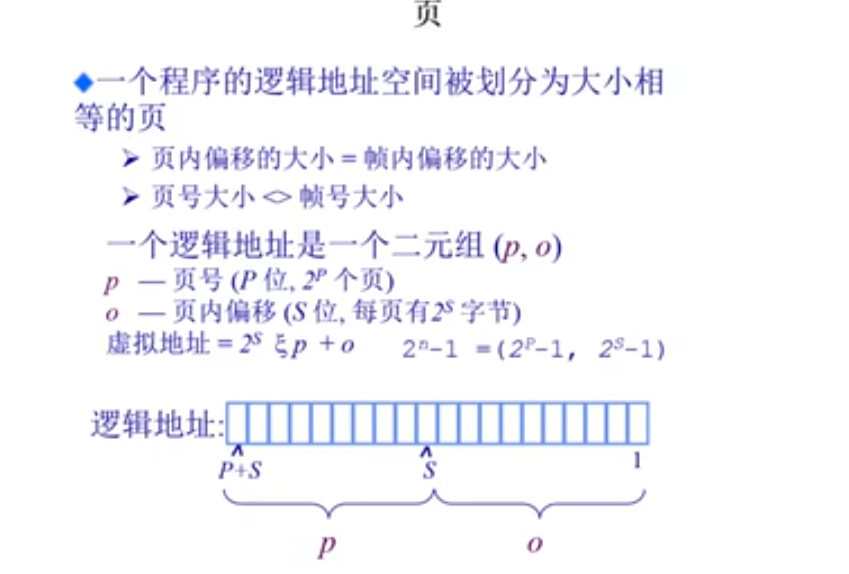
页 (Page)
逻辑地址空间被划分为相同大小的页,页的寻址方式与帧类似。逻辑地址由页号和页内偏移量组成。
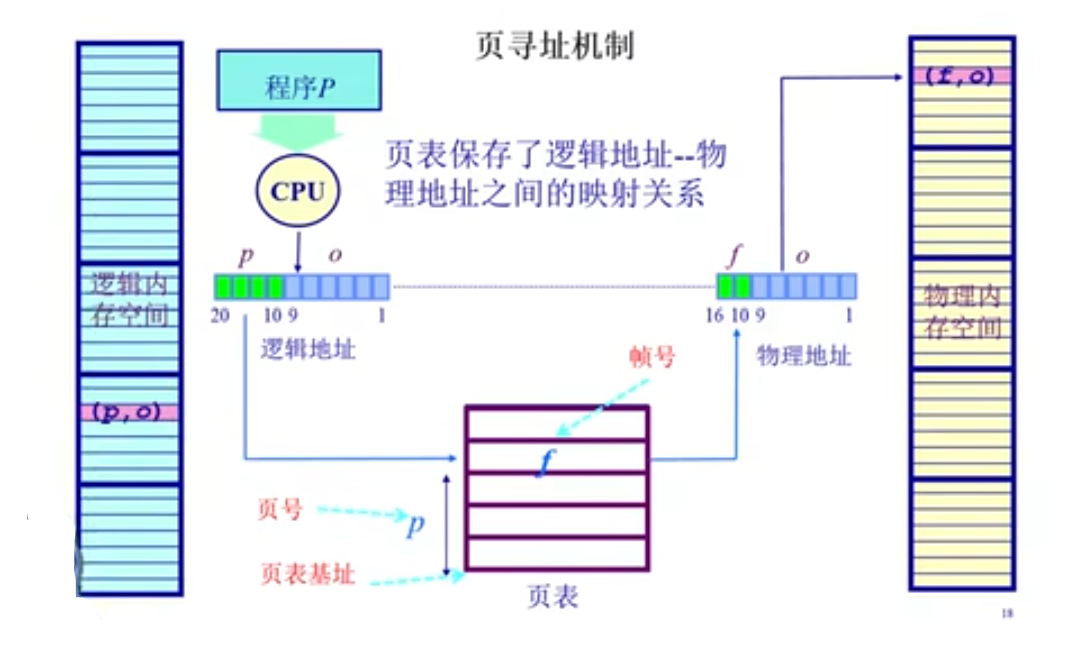
地址转换
程序执行时,需要将逻辑地址转换为物理地址。通过页号索引页表,查询到对应的帧号,再加上偏移量,最终得到物理地址。
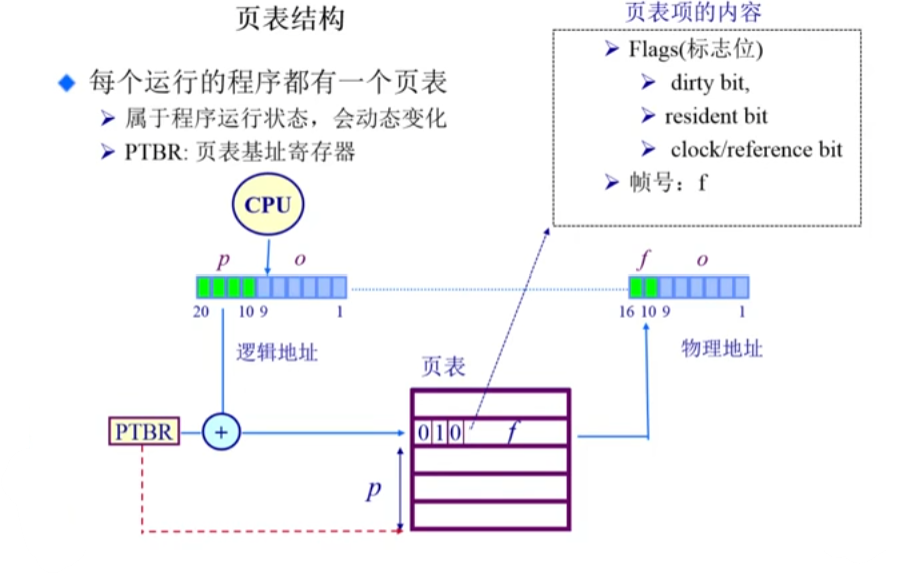
页表
页表在分页机制中起着至关重要的作用。为了提高效率、节省空间,页表需要设计得既高效又可靠。
页表的结构如下图所示:
下图展示了页表在地址转换中的实际应用:
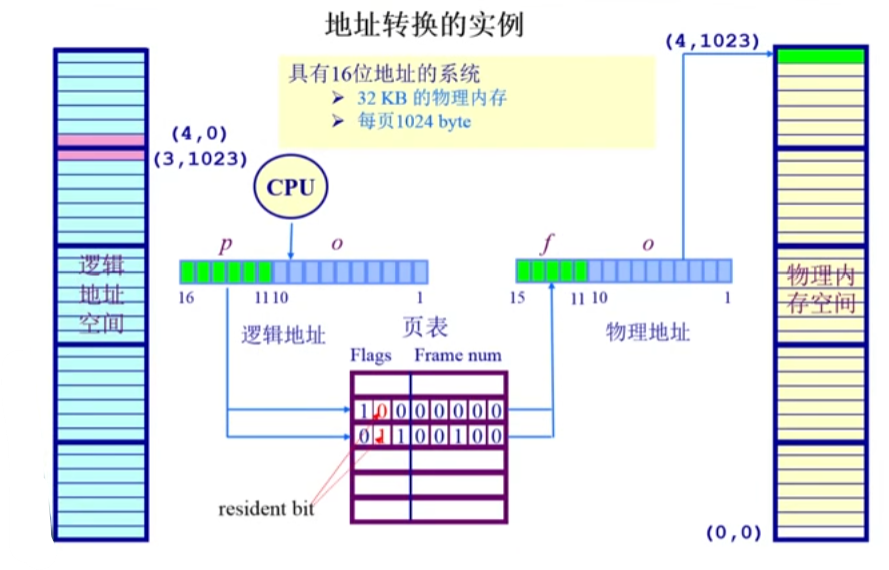
从图中可以看出,逻辑地址和物理地址的偏移量相同,但它们的页号不同。驻留位(Resident Bit)表示逻辑地址指向的物理页是否存在。如果驻留位为1,说明该页存在;若为0,则表示该页未加载到物理内存,访问时会触发内存访问异常。
分页机制的性能问题
两次内存访问:每次访问一个内存单元需要两次内存访问:一次用于获取页表项,另一次用于访问数据。
页表可能非常大:例如,在64位机器上,如果每页为1024字节,那么页表的大小就非常庞大(2的54次方)。
为了解决这些问题,可以采用以下方法:
缓存(Caching)
间接访问(Indirection)
缓存(Caching)
使用 Translation Look-aside Buffer(TLB)来缓存近期访问的页表项,以提高访问速度。
TLB使用关联内存来快速查找页表项
如果TLB命中,物理页号能够快速获取
若未命中,则需要从内存中查找页表项,并将其更新到TLB中
通过TLB,页表查询的速度得到了显著提升。
间接(Indirection)访问
为了减少页表的空间占用,可以使用多级页表。将页表分为多个层级,一级页表存储二级页表的起始地址,二级页表则存储具体的帧号。通过这种方式,虽然会增加一些查询开销,但可以节省空间,且在查询时通过TLB提高访问速度。
反向页表(Inverted Page Table)
反向页表的出现是为了减少页表大小与逻辑地址空间大小之间的紧密关系。通过使用页帧号作为索引,页表的大小与逻辑地址空间无关。
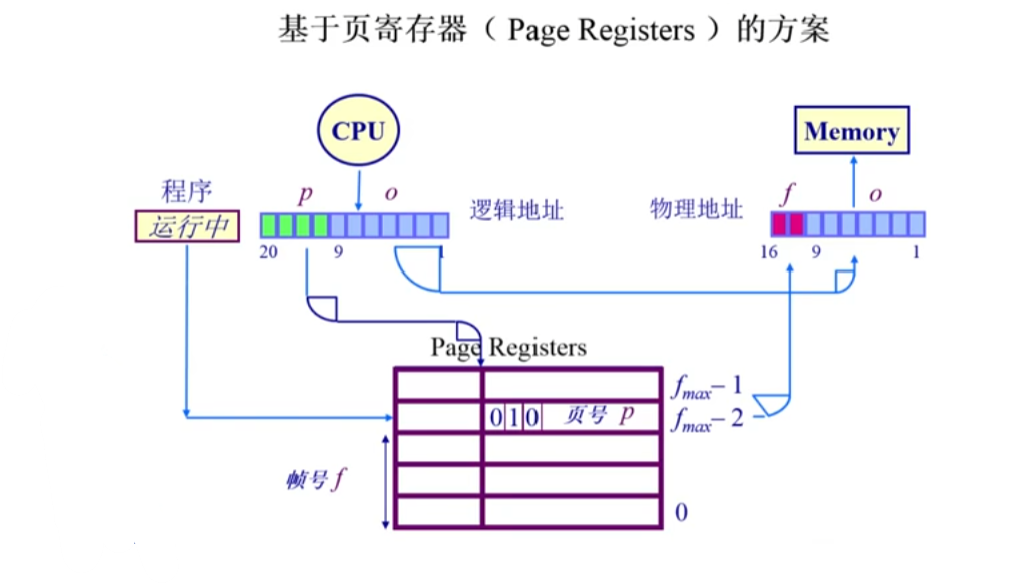
尽管这种方法大大减少了页表占用的空间,但查询效率降低。为了优化查询性能,可以使用哈希来实现查找,并结合类似TLB的机制来缓解哈希碰撞和计算开销。
总结
非连续内存分配通过分段和分页机制,提供了更灵活的内存管理方式,能够有效地解决内存碎片问题。分页是现代计算机系统中广泛采用的技术,涉及页表、TLB等多项技术手段以提高效率。
尽管分页机制存在性能瓶颈,如内存访问的两次查询和页表大小问题,但通过缓存和多级页表等优化手段,能够有效缓解这些问题。反向页表作为一种新兴的技术,通过改变页表索引方式,进一步减少了页表占用的空间。