Java 并发基础知识笔记
为什么需要多线程?
从根本上,多线程技术的目的就是让我们的程序能够更加高效、快速地执行。
1. 更多的处理器核心
现在的处理器上普遍有多个处理核心,比以往更加擅长并行计算。另外,线程是一个处理器最小的调度单元,而一个线程同一时刻只能运行在一个处理器核心上,如果是单线程,那同一时刻只会有一个处理器核心被占用,其他就都被浪费了,处理器有再多核心都无法提升程序执行效率。
而相反,如果使用多线程技术,那并行执行这些线程就可以充分利用处理器多核的优势,让程序执行地更快。
2. 更快的响应速度
在传统单程序中,很多时候如果多个操作在一个线程中串行执行,那效率是不高的,一个操作需要等待上一个操作完成才能继续执行。而如果把其中相互依赖程度不高的的操作拆分出来,放到不同的线程中去异步执行,这样就能避免其他操作造成的不必要的阻塞,会带来更好的执行效率。
并发安全问题
概念上来说,并发安全是指在多个线程或进程同时访问和操作共享数据或资源时,程序能够正确地执行,不会出现数据不一致、数据错误或者其他不符合预期的结果。
如下代码演示了一个并发不安全的场景。使用 500 个线程来并发对 threadUnsafe 对象中的 count 变量进行自增操作,预期执行结果应当是 500,但实际执行情况却不确定,可能会小于 500
public class ThreadUnsafeDemo {
public static void main(String[] args) throws InterruptedException {
int executeTime = 500;
ThreadUnsafe threadUnsafe = new ThreadUnsafe();
CountDownLatch countDownLatch = new CountDownLatch(executeTime);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < executeTime; i++) {
executorService.execute(() -> {
threadUnsafe.increment();
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
System.out.println(threadUnsafe.getCount());
}
}
class ThreadUnsafe {
private int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}这是其中某一次执行的结果:
至于为什么会发生线程不安全的问题,在 Java 中主要有三种原因:
可见性:由“线程本地内存”引起
原子性:时分复用引起
有序性:指令重排序引起
可见性
Java 中所有实例域、静态域和数组元素都存储在堆内存中,堆内存在线程之间共享,只有这些共享变量才会有内存可见性问题,受到 Java 内存模型(JMM)的影响,而局部变量、方法定义参数和异常处理器参数不会在线程之间共享,不存在类似问题。
Java 内存模型的抽象示意图如下所示:
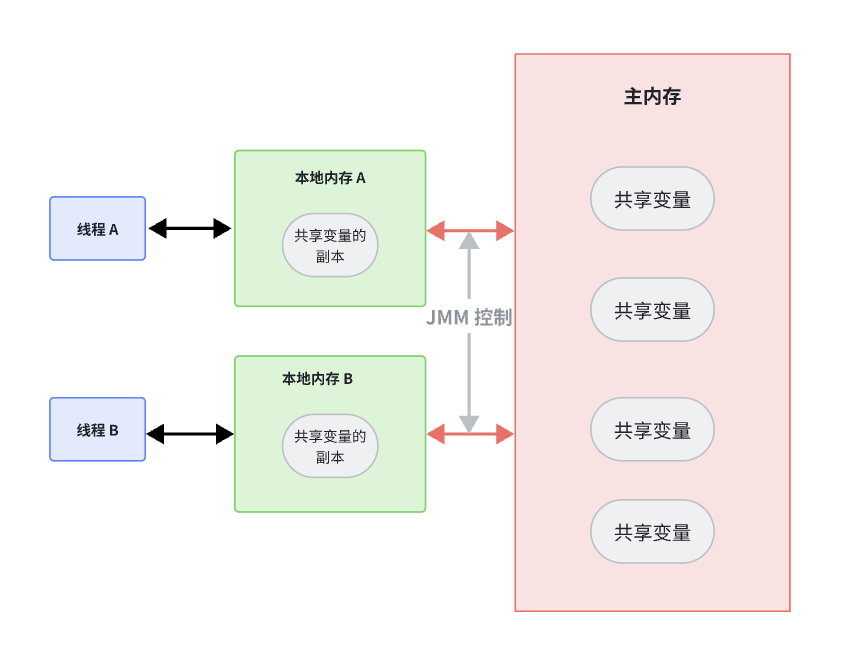
在这个模型中,如果线程 A 和线程 B 要进行通信的话,就必须要经过如下 2 个步骤:
首先,线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中去
然后,线程 B 到主内存中去读取线程 A 之前已更新过的共享变量
如果在这两步之前,线程 B 操作共享变量,会发生问题:线程 A 对共享变量的修改没有被 B 看到,B 使用的还是共享变量原来的值,这将可能导致程序的错误。JMM 通过控制主内存和每个线程的本地内存之间的交互,为我们提供内存可见性的保证
原子性
原子性在概念上,就是一个操作或者多个操作要么全部执行并且执行的过程不会被打断,要么就不执行。我们日常对变量有以下常见操作:
// 1. 变量赋值
i = 1;
// 2. 变量自增
i++;在 Java 中,变量赋值可以视为单步的原子操作,但是变量的自增不是原子操作,它需要 3 条指令:
将变量 i 从内存读取到 CPU 寄存器
在 CPU 寄存器中执行自增操作
将结果 i 写回到内存中
如果自增操作在多线程环境下运行,也就是一开始的代码中的场景,一个线程执行指令 1 后,另一个线程执行完了 3 条指令,再切换回第一个线程执行完后续两条指令,就会导致 i 的值实际只被自增了一次,第二个线程的操作被覆写了。这也是为什么在之前的程序里,最终结果可能会少于 500
有序性
有序性指的就是程序执行的顺序按照代码的先后顺序执行。Java 里执行程序的时候为了提高性能,编译器和处理器常常会对指令进行重排序,而重排序在多线程场景下,就有可能导致内存的可见性问题,需要我们使用一些处理工具(如,volatile,锁等)进行控制
Java 解决并发问题的方法:JMM(Java 内存模型)
Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法,这些方法包括:
volatile、synchronized 和 final 关键字
Happens - Before 规则
volatile 关键字
volatile 关键字可以保障可见性和有序性:
可见性:在给变量增加 volatile 关键字之后,线程修改变量不会只修改本地内存,JMM 还会触发本地内存到主内存的回写,而线程尝试读取 volatile 关键字修饰的变量之后,不会再从本地内存中读,而是转而去读取主内存中的变量值
有序性:
通过对 volatile 域的 Happens - Before 规则实现:对一个 volatile 域的写,Happens - Before 于任意后续对这个 volatile 域的读
volatile 禁止重排序
synchronized 关键字
synchronized 关键字通过加锁来实现并发安全,synchronized 可以修饰普通方法、静态方法和代码块。synchronized 修饰普通方法时,默认锁是当前的实例对象,修饰静态方法时,默认锁是当前类的 Class 对象,修饰代码块时,锁是括号中指定的对象,当线程尝试执行被 synchronized 关键字修饰的代码时,只有获取到对应的锁,才能继续执行。
synchronized 的加锁操作利用了对象的监视器(Monitor),获取锁的过程是排他的,即同一时刻只有一个线程能够获取到 synchronized 所指定的对象的监视器。竞争失败的线程会进入到同步队列 SynchronizedQueue 中,状态变成 BLOCKED,在获取到锁的线程释放锁之后,释放操作会唤醒同步队列中的所有线程,使其重新尝试对监视器的获取,即 synchronized 实现的是非公平锁。
synchronized 实现的是可重入锁,即同一个线程可以反复给一个对象加锁。这是使用一个 Monitor 计数器实现的,线程获取到锁之后和加锁操作会使计数器值加一,释放锁会使得计数器值减一,最终当 Monitor 计数器的值为 0 时,才真正表示释放了锁。
另外,对 synchronized 锁也有 Happens - Before 规则,即监视器锁规则:对同一个监视器解锁,Happens - Before 与对这个监视器的加锁。
final 关键字
对 final 关键字修饰的数据有一系列重排序禁止规则,按数据类型可以分为:
基本数据类型:
对 final 域的写操作:禁止 final 域写和构造方法重排序,也就是禁止把对 final 域的写操作重排序到构造方法之外,以此保证这个对象对所有线程可见的时候,对象的所有 final 域都已经初始化过
对 final 域的读操作:禁止初次读对象的引用与读该对象包含的 final 域的重排序,也是确保在读 final 域之前,它已经被初始化过了
引用数据类型:
额外增加约束:禁止“在构造函数内对一个 final 修饰的对象的成员域的写入”与“随后将这个被构造的对象的引用赋值给引用变量”的重排序,这样保证了这个对象已经被初始化过
Happens - Before 规则
单一线程顺序规则:在一个线程内,程序前面的操作 happens - before 后面的操作
监视器锁规则:对一个锁的解锁操作 happens - before 后面对一个锁的加锁操作
volatile 变量规则:对一个 volatile 变量的写操作 happens - before 后面对这个变量的读操作
传递性规则:如果 A happens - before B,B happens - before C,则 A happens - before C
线程 start() 规则:如果线程 A 执行操作 ThreadB.start(),那么 A 线程的 ThreadB.start() 操作 happens - before 线程 B 中的任何操作
join 规则:如果线程 A 执行操作 ThreadB.join() 并成功返回,那么线程 B 内的任意操作 happens - before 线程 A 从 ThreadB.join() 操作成功返回
线程中断规则:对线程 interrupt() 方法的调用 happens - before 被中断线程的代码检测到中断事件的发生,可以通过 interrupted() 方法检测到是否有中断发生
对象终结规则:一个对象的初始化完成(构造函数执行结束)happens - before 它的 finalize() 方法的开始
总结
为什么需要多线程?
多线程的根本目的在于提升程序执行效率,充分利用现代多核处理器的并行计算能力。单线程程序只能利用一个核心,而多线程能够让多个任务同时运行,实现更快的处理速度。此外,多线程还能提高程序的响应速度,通过将独立的操作异步执行,避免不必要的阻塞
并发安全问题
多线程带来了并发的复杂性,主要体现在以下三点:
可见性:线程无法及时看到共享变量的最新值。
原子性:某些操作在多线程环境下无法保证完整执行。
有序性:指令重排序可能导致意外行为。
Java 的解决方案
Java 提供了内置的内存模型(JMM)和工具来保障并发安全:
volatile 关键字:保障变量的可见性和有序性
synchronized 关键字:通过锁机制确保原子性和线程间协作
Happens-before 规则:定义了操作的执行顺序,为多线程编程提供内存可见性保证
通过合理利用这些机制,可以有效避免并发问题,编写高效、安全的多线程程序